With the popularity of LLM (Large Language Model), vector databases have also become a hot topic. With just a few lines of simple Python code, a vector database can act as a cheap but highly effective “external brain” for your LLM. But do we really need a specialized vector database?
Why does LLM need vector search?
First, let me briefly introduce why LLM needs to use vector search technology. Vector search is a problem that has been around for a long time. The process of finding the most similar object in a collection given an object is vector search. Text/images, etc. can be converted into a vector representation, and the similarity problem of text/images can be transformed into a vector similarity problem.

Text search (credit)
In the example above, we convert different words into a three-dimensional vector. Therefore, we can intuitively display the similarity between different words in a 3D space. For example, the similarity between “student” and “school” is higher than the similarity between “student” and “food”.
Returning to LLM, the limitation of the context window length is a major challenge. For instance, ChatGPT 3.5 has a context length limit of 4k tokens. This poses a significant problem for LLM’s context-learning ability and negatively impacts the model’s user experience. However, vector search provides an elegant solution to this problem:
- Divide the text that exceeds the context length limit into shorter chunks and convert different chunks into vectors (embeddings).
- Before inputting the prompt to LLM, convert the prompt into a vector (embedding).
- Search the prompt vector to find the most similar chunk vector.
- Concatenate the most similar chunk vector with the prompt vector as the input to LLM.
This is like giving LLM an external memory, which allows it to search for the most relevant information from this memory. This memory is the ability brought by vector search. If you want to learn more details, you can read these articles (Article 1 and Article 2), which explain it more clearly.
Why is vector database so popular?
In LLM, the vector database has become an indispensable part, and one of the most important reasons is its ease of use. After being used in conjunction with OpenAI Embedding models (such as text-embedding-ada-002), it only takes about ten lines of code to convert a prompt query into a vector and perform the entire process of vector search.
def query(query, collection_name, top_k=20):# Creates embedding vector from user query
embedded_query = openai.Embedding.create(
input=query,
model=EMBEDDING_MODEL,
)["data"][0]['embedding']
near_vector = {"vector": embedded_query} # Queries input schema with vectorized user query
query_result = (
client.query
.get(collection_name)
.with_near_vector(near_vector)
.with_limit(top_k)
.do()
)
return query_result
In LLM, vector search mainly plays a role in recall. Simply put, recall is finding the most similar objects in a candidate set. In LLM, the candidate set is all chunks, and the most similar object is the chunk that is most similar to the prompt. In the reasoning process of LLM, vector search is regarded as the main implementation of recall. It is easy to implement and can use OpenAI Embedding models to solve the most troublesome problem of converting text into vectors. The remaining part is an independent and clean vector search problem, which can be well completed by current vector databases. Therefore, the entire process is particularly smooth.
As the name suggests, vector database is a database specifically designed for the special data type of vectors. The similarity calculation of vectors was originally an O(n²) complexity problem because it required comparing all vectors in the set pairwise. Therefore, the industry proposed the Approximate Nearest Neighbor (ANN) algorithm. By using the ANN algorithm, the vector index is constructed by pre-calculating in the vector database, using the idea of trading space for time, which greatly speeds up the process of similarity calculation. This is similar to the index in traditional databases.
Therefore, vector databases not only have strong performance but also excellent ease of use, making them a perfect match for LLM! (Really?)
Perhaps a general-purpose database would be better?
We’ve talked about the advantages and benefits of vector databases, but what are their limitations? A blog post by SingleStore provides a good answer to this question:
Vectors and vector search are a data type and query processing approach, not a foundation for a new way of processing data. Using a specialty vector database (SVDB) will lead to the usual problems we see (and solve) again and again with our customers who use multiple specialty systems: redundant data, excessive data movement, lack of agreement on data values among distributed components, extra labor expense for specialized skills, extra licensing costs, limited query language power, programmability and extensibility, limited tool integration, and poor data integrity and availability compared with a true DBMS.
There are two issues that I think are important. The first is the issue of data consistency. During the prototyping phase, vector databases are very suitable, and ease of use is more important than anything else. However, a vector database is an independent system that is completely decoupled from other data storage systems such as TP databases and AP data lakes. Therefore, data needs to be synchronized, streamed, and processed between multiple systems.
Imagine if your data is already stored in an OLTP database such as PostgreSQL. To perform vector search using an independent vector database, you need to first extract the data from the database, then convert each data point into a vector using services such as OpenAI Embedding, and then synchronize it to a dedicated vector database. This adds a lot of complexity. Furthermore, if a user deletes a data point in PostgreSQL but it is not deleted in the vector database, then there will be data inconsistency issues. This issue can be very serious in actual production environments.
-- Update the embedding column for the documents table
UPDATE documents SET embedding = openai_embedding(content) WHERE length(embedding) = 0;-- Create an index on the embedding column
CREATE INDEX ON documents USING ivfflat (embedding vector_l2_ops) WITH (lists = 100);-- Query the similar embeddings
SELECT * FROM documents ORDER BY embedding <-> openai_embedding('hello world') LIMIT 5;
On the other hand, if everything is done in a general-purpose database, the user experience may be simpler than with an independent vector database. Vectors are just one data type in a general-purpose database, not an independent system. This way, data consistency is no longer an issue.
The second issue is with query language. The query language of vector databases is typically designed specifically for vector search, so there may be many limitations in other types of queries. For example, in metadata filtering scenarios, users need to filter based on certain metadata fields. The filtering operators supported by some vector databases are limited.
In addition, the supported data types for metadata are also very limited, usually only including String, Number, List of Strings, and Booleans. This is not friendly for complex metadata queries.
If traditional databases can support the vector data type, then the aforementioned issues do not exist. Firstly, data consistency is already taken care of as TP or AP databases are existing infrastructure in production environments. Secondly, the issue of query language no longer exists because vector data type is just one data type in the database, so queries for vector data type can use the native query language of the database, such as SQL.
Detailed explanation
However, it is unfair to only compare the disadvantages of vector databases. There are several counterpoints to consider:
- Ease of Use: Vector databases are designed with ease of use in mind, and users can easily work with them without worrying about the underlying implementation details. However, integrating them with other data storage systems can be a challenge, as mentioned earlier.
- Performance: Vector databases have a significant advantage over traditional databases in terms of performance for certain use cases. Their design for vector search allows for fast and efficient similarity searches on large-scale datasets with high-dimensional vectors.
- Metadata Filtering: While metadata filtering capabilities in vector databases may be limited, they can still meet the needs of most business scenarios. However, for more complex metadata queries, a hybrid approach may be needed, where metadata is stored in a separate database or data lake and linked to the vector data in the vector database.
How can you address these issues? In the following section, I will provide my perspective by answering these questions.
Vector databases are easy to use
While it is true that vector databases are easy to use, this is not unique to them. The ease of use of vector databases is mainly due to their abstraction of a specific domain, which allows them to be specifically designed for the most commonly used machine learning programming language, Python, and optimized for vector search scenarios. However, if traditional databases could also support the vector data type, they could offer similar ease of use.
In addition, traditional databases can provide Python SDKs and other integrated tools to meet the needs of most scenarios, as well as standard SQL interfaces to handle more complex query scenarios. Therefore, it is not necessary to use a vector database solely for its ease of use.
Another advantage of vector databases is their distributed design, which allows them to scale horizontally to meet the data volume and QPS requirements of users. However, traditional databases can also meet these requirements through distributed systems. Nevertheless, the decision to use a distributed system should be based on the actual needs of the data volume and QPS requirements, as well as the associated costs.
In summary, while vector databases have their advantages, traditional databases can also provide similar ease of use and distributed capabilities if they support the vector data type. Therefore, the choice between a vector database and a traditional database should be based on the specific needs of the application and the available resources.
Vector databases have better performance
To investigate the performance of vector databases in LLM scenarios, a naive benchmark of vector retrieval was conducted. The benchmark involved N randomly initialized 256-dimensional vectors, and the query time for the top-5 nearest neighbors was measured for different scales of N. Two different methods were used for the test:
- Numpy was used to perform real-time calculation, which executed completely accurate, non-precomputed nearest neighbor calculation.
- Hnswlib was used to precompute approximate nearest neighbors.
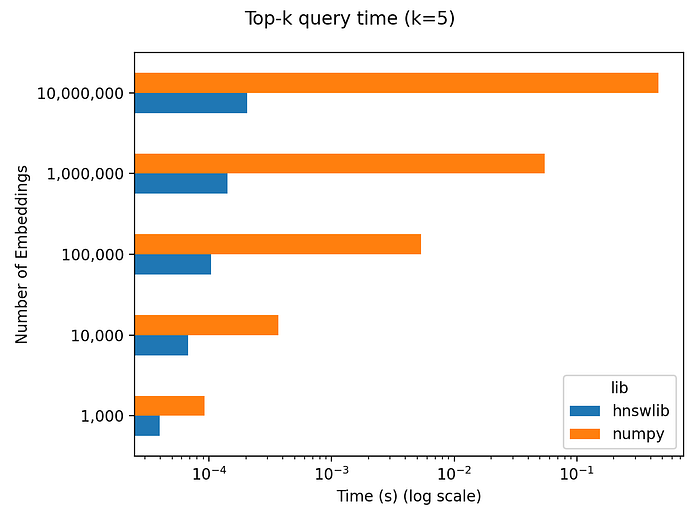
Benchmark (credit)
The benchmark results show that, at the scale of 1 million vectors, the delay of real-time calculation using Numpy is approximately 50ms. Using this as a benchmark, we can compare the time spent on LLM inference after completing vector search. For instance, the 7B model requires approximately 10 seconds for inference on 300 Chinese characters on an Nvidia A100 (40GB). Therefore, even if the query time for real-time accurate calculation of the similarity of 1 million vectors using Numpy is considered, it only accounts for 0.5% of the total delay in the end-to-end LLM inference. Thus, in terms of delay, the benefits brought by vector databases may be overshadowed by the delay of LLM itself in the current LLM scenario. Therefore, we need to also consider throughput. The throughput of LLM is much lower than that of vector databases. Thus, I do not believe that throughput is the core issue in this scenario.
If performance is not the primary concern, what factors will determine the user’s choice? I think it is the overall ease of use, including ease of use for both usage and operation, consistency, and other solutions to database-related issues. Traditional databases have mature solutions for these problems, while vector databases are still in the early stages of development.
Metadata filtering can still meet the needs of most business scenarios
When considering metadata filtering, it’s important to note that it’s not just a matter of the number of supported operators. Consistency of data is also a crucial factor. Metadata in vectors is essentially data in traditional databases, while vectors themselves are indexes of the data. Therefore, it’s reasonable to consider storing both vectors and metadata in traditional databases.
Traditional databases do have the capability to support vector data types and provide similar ease of use and distributed capabilities as vector databases. Furthermore, traditional databases have mature solutions to ensure data consistency and integrity, such as transaction management and data backup and recovery.
Vectors in traditional databases
Since we see vectors as a new data type in traditional databases, let’s take a look at how to support vector data types in traditional databases, using PostgreSQL as an example. pgvector is an open-source PostgreSQL plugin that supports vector data types. pgvector uses exact calculation by default, but it also supports building an IVFFlat index and precomputing ANN results using the IVFFlat algorithm, sacrificing calculation accuracy for performance.
pgvector has done an excellent job of supporting vectors and is used by products such as supabase. However, the supported index algorithm is limited, with only the simplest IVFFlat algorithm supported, and no quantization or storage optimization is implemented. Moreover, the index algorithm of pgvector is not disk-friendly and is designed for use in memory. Therefore, vector index algorithms designed for disk, such as DiskANN, are also valuable in the traditional database ecosystem.

Extending pgvector can be challenging due to its implementation in the C programming language. Despite being open-source for two years, pgvector currently has only three contributors. While the implementation of pgvector is not particularly complex, it may be worth considering rewriting it in Rust.
Rewriting pgvector in Rust can enable the code to be organized in a more modern and extensible way. Rust’s ecosystem is also very rich, with existing Rust bindings such as faiss-rs.
pgvecto.rs
As a result, pgvecto.rs was created. pgvecto.rs currently supports exact vector query operations and three distance calculation operators. Work is underway to design and implement index support. In addition to IVFFlat, we also hope to support more indexing algorithms such as DiskANN, SPTAG, and ScaNN. We welcome contributions and feedback from the community!
pgvecto.rs offers a modern and extensible codebase with improved performance and concurrency. Its design and implementation allow seamless integration with other machine learning libraries and tools, making it an ideal choice for similarity search scenarios.
With ongoing development, pgvecto.rs aims to be a valuable tool for data scientists and machine learning practitioners. Its support for various indexing algorithms and its ease of use make it a promising candidate for large-scale similarity search applications. We look forward to continuing development and contributions from the community.
-- call the distance function through operators-- square Euclidean distance
SELECT array[1, 2, 3] <-> array[3, 2, 1];
-- dot product distance
SELECT array[1, 2, 3] <#> array[3, 2, 1];
-- cosine distance
SELECT array[1, 2, 3] <=> array[3, 2, 1];-- create table
CREATE TABLE items (id bigserial PRIMARY KEY, emb numeric[]);
-- insert values
INSERT INTO items (emb) VALUES (ARRAY[1,2,3]), (ARRAY[4,5,6]);
-- query the similar embeddings
SELECT * FROM items ORDER BY emb <-> ARRAY[3,2,1] LIMIT 5;
-- query the neighbors within a certain distance
SELECT * FROM items WHERE emb <-> ARRAY[3,2,1] < 5;
Future
As LLMs gradually move into production environments, infrastructure requirements are becoming increasingly demanding. The emergence of vector databases is an important addition to the infrastructure. We do not believe that vector databases will replace traditional databases, but rather that they will each play to their strengths in different scenarios. The emergence of vector databases will also promote traditional databases to support vector data types.
We hope that pgvecto.rs can become an important component of the Postgres ecosystem, providing better vector support for Postgres. Its implementation in Rust and support for various indexing algorithms make it a promising candidate for large-scale similarity search applications. We believe that its development and contributions from the community will help it become a valuable tool for data scientists and machine learning practitioners.
